Versity’s ScoutAM offers a simple but powerful platform for managing, preserving, and supporting AI-driven analysis of exponentially increasing collections of unstructured data. It is the first scalable, modular, and economically efficient mass storage solution for exabyte-scale data orchestration, designed to meet the demands of AI and high-performance workloads.
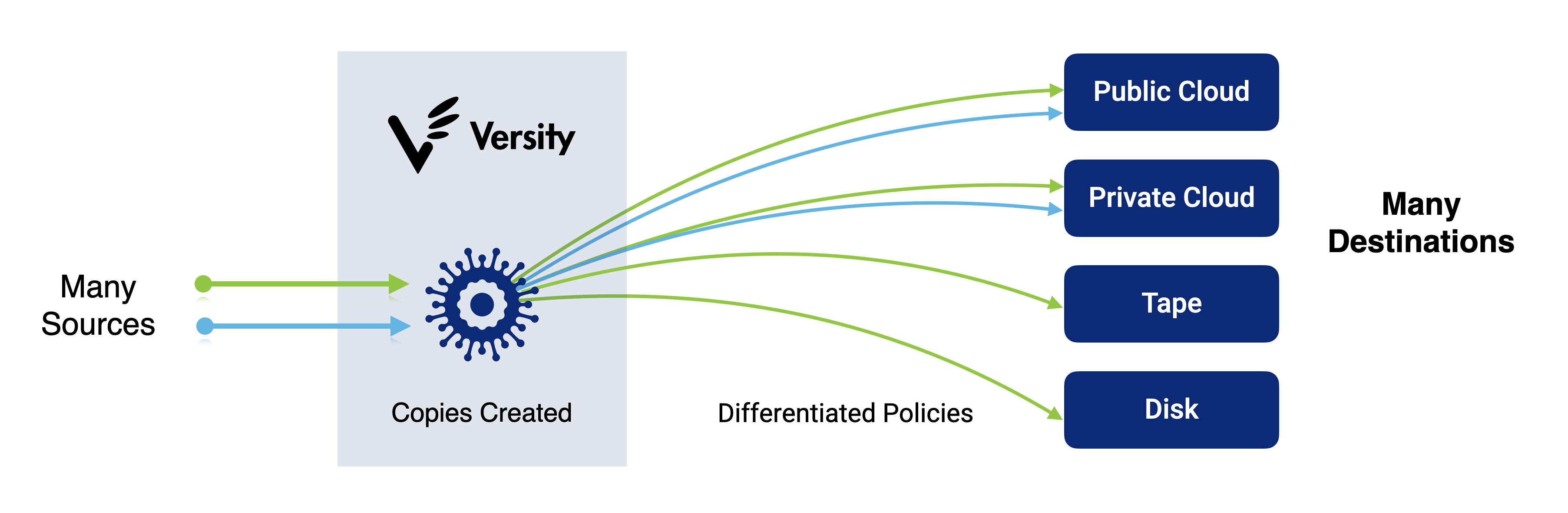
ScoutAM enables full data visibility, seamless access, and intelligent usage, empowering both teams and applications to work efficiently. With a policy-driven approach, it eliminates risk and complexity by automating data placement across configurable storage pools, including high-performance disk, hybrid object storage, cloud, and tape.
While ScoutAM is engineered for exascale and AI-driven workloads, it is also designed for ease of use and quick startup. In fact, installation and configuration are so simple that they can be completed in as little as 30 minutes. The modern, graphical user interface is intuitive and easy to learn, even for teams managing complex AI and HPC environments. Our API-driven monitoring, alerting, and configuration tools provide users with clear visibility and control over their data.
High Availability
ScoutAM delivers high availability even in demanding AI and HPC environments, remaining fully operational despite the loss of servers within a cluster. Depending on the cluster’s size and the quorum definitions, ScoutAM can tolerate the loss of one or more servers with no impact on availability or continuity of services. Failover is built into the ScoutAM platform and does not require complex external failover or HA tools.
Ultimate Disaster Recovery
ScoutAM supports recovery of all data elements directly from the mass storage media, without the use of any specialized software. All information required to restore a data collection resides on the physical media with the data. Plus, asynchronous read-only remote replication allows metadata, cache data, and mass storage or archival data to be replicated to one or more disaster recovery or secondary locations to ensure continuity of operations.
Open source metadata combined with open source data formats gives customers complete control over data collections and aligns with long-term data preservation and data autonomy goals.
ScoutAM is a modular platform that can be expanded incrementally to increase capacity and performance over time.
Hybrid Cloud
ScoutAM supports both on-premises S3 object storage devices and Amazon, Azure, and Google public cloud storage services. High performance cloud capabilities enable Versity sites to benefit from the flexibility of hybrid tape and cloud infrastructure.
Object to Tape
ScoutAM leverages the high-performance, low-overhead Versity S3 Gateway for ingesting S3 object data, seamlessly storing it on tape for efficient, cost-effective long-term protection.
Automated Orchestration
ScoutAM offers robust support for crafting and automatically implementing data orchestration policies, providing streamlined, customized management of data workflows, and ensuring efficient and precise control over how data is handled and processed in alignment with unique organizational needs.
API Coverage
The ScoutAM platform includes extensive API coverage to ease integration with third party tools and site specific workflows, enabling seamless integration with AI pipelines and HPC applications. All elements of the ScoutAM GUI are accessed by published APIs.
Zero Data Migration
ScoutAM is the first mass storage platform to support data formats from third party platforms, including HPE DMF, IBM HPSS and Oracle OHSM. Format support eliminates the need for costly and time consuming data migrations.
How ScoutAM Works
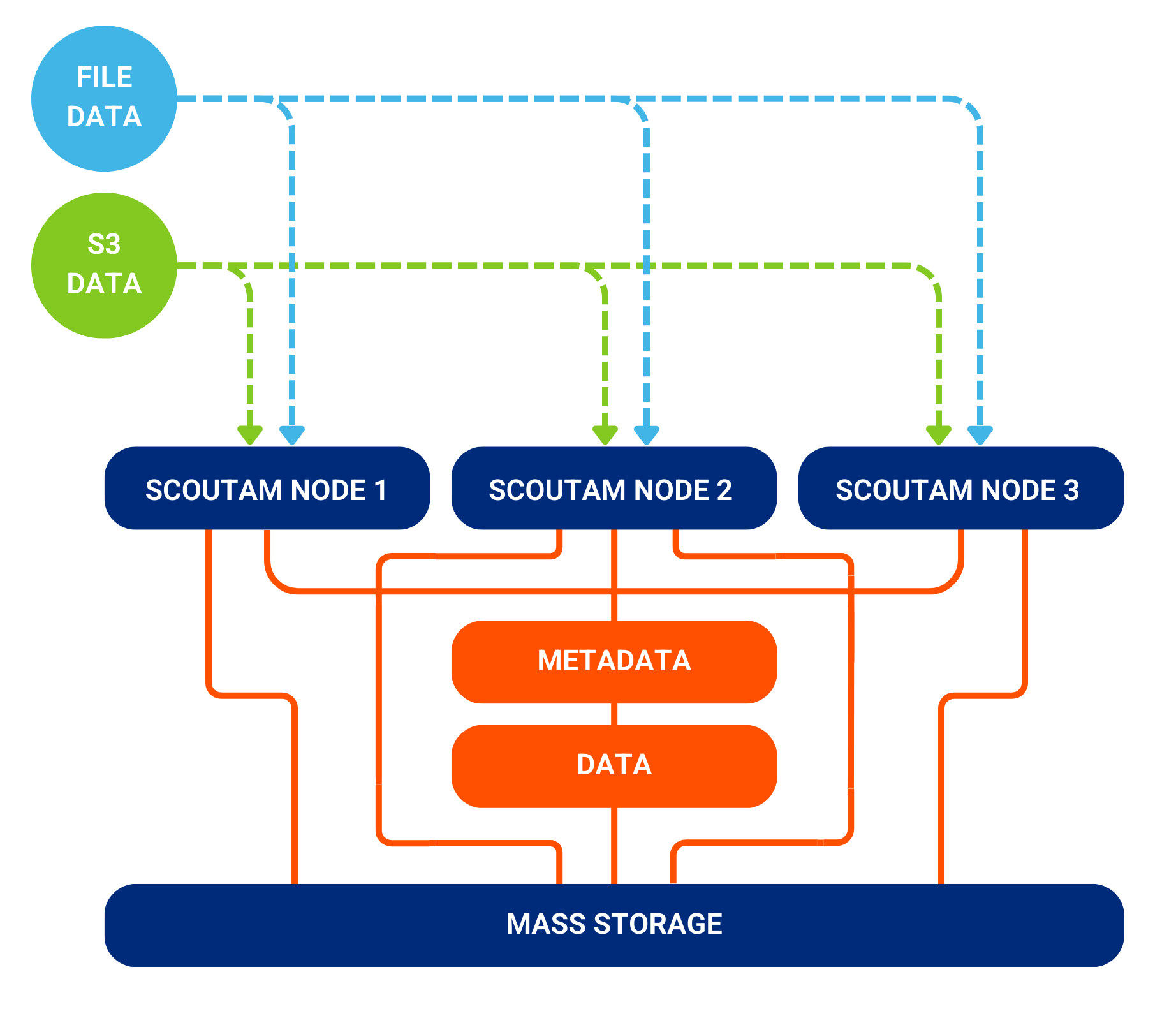
Data is ingested from primary sources to the ScoutAM cache using industry-standard file and object protocols.
Metadata is recorded and separated from data, where it remains permanently online.
Data resides in the cache while copies are generated, and thereafter for a defined time interval or until the cache space is needed for new data.
Configurable policies are applied to cache data to generate the desired number of copies and write the copies to the defined destination.
Policy definitions enable grouping by data type, application, size, user or group.
These definitions also set boundaries on the time that can pass before the creation of copies and on the data set size.
The ability to apply different policies and coalesce random incoming data streams into efficient streaming data sets is one of the platform’s core functions.
Discover unparalleled scalability with ScoutAM. Designed to meet the ever-evolving demands of modern data management in HPC and AI workflows. ScoutAM seamlessly scales both horizontally and vertically to align with your needs: add nodes to boost performance or maximize the power of each node by leveraging every resource and core to its fullest. Whether you’re expanding your infrastructure or optimizing individual nodes, ScoutAM adapts effortlessly, delivering peak performance and reliability at any scale.
Optimize Power and Cost
Unlock the full potential of sustainable, AI-ready storage management with ScoutAM. Designed to help businesses optimize both energy consumption and storage costs, ScoutAM seamlessly integrates with lower-power devices to deliver energy-efficient operations that reduce your carbon footprint and utility bills. Its intelligent automation simplifies the use of lower-cost storage tiers, ensuring maximum value without compromising accessibility. ScoutAM helps you build a smarter, greener storage foundation, optimizing resources without compromising performance or accessibility.
Customer Spotlight
“We are very happy with Versity’s solution. We were impressed with the Zero Data Migration capability, 150PBs of data in one week! The solution was very easy to install, configure, and operate – we were up and running in no time. The modern S3 and REST APIs with broad coverage for external tooling and applications to support our data-driven workflows was a home run because we can now easily utilize Kafka, Grafana, and Keycloak to further boost our scientific mission. We also recognized Versity’s continued commitment to mass data management through their vibrant roadmap and a rapid feature release cadence. Coupled with Versity’s scalable, modular, and simple upgrade approach, we know we have a future-proof solution.”
Chris Schlipalius Team Lead & Senior Systems Administrator
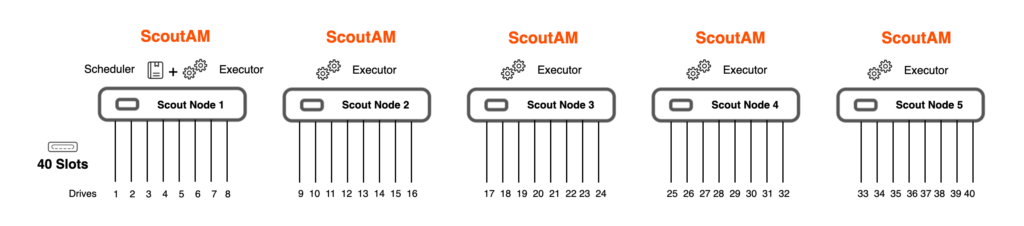
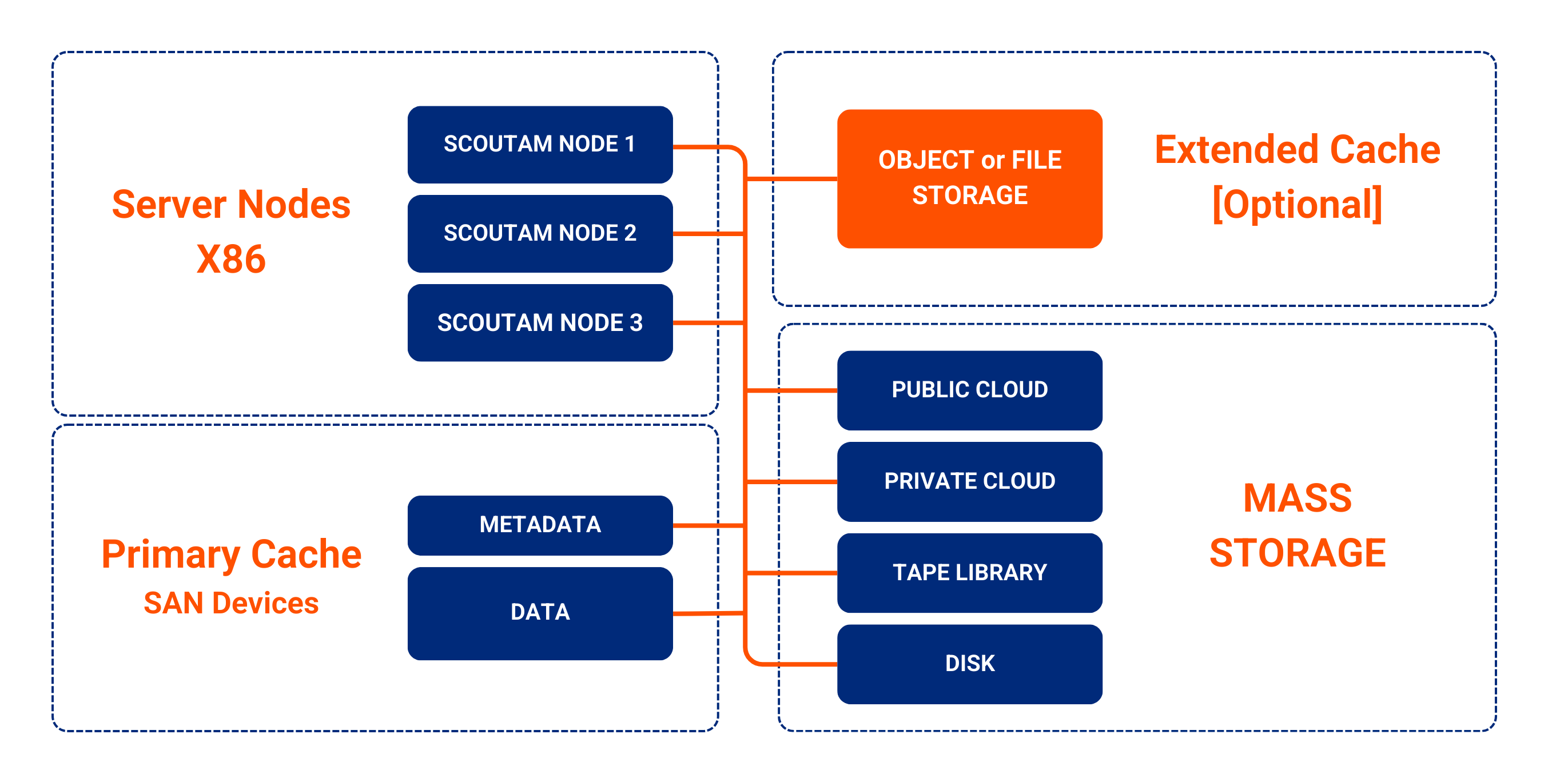
Each server in a ScoutAM cluster can deliver all of the platform services and scale to increase total performance. This modular architecture ensures availability by eliminating single points of failure and delivers scalability by removing bottlenecks for metadata processing and parallel data movement between primary and mass storage environments.
The ScoutAM runtime application is present on all nodes in the cluster. Each node runs a ScoutAM executor, and the cluster runs a ScoutAM scheduler – a highly scalable virtual role that is not dependent on any specific server in the cluster. Each ScoutAM node can deliver data through as many data channels as the server configuration allows and will deliver approximately 10 GB/s of aggregate throughput per node for mid-range servers.
Featured Capabilities
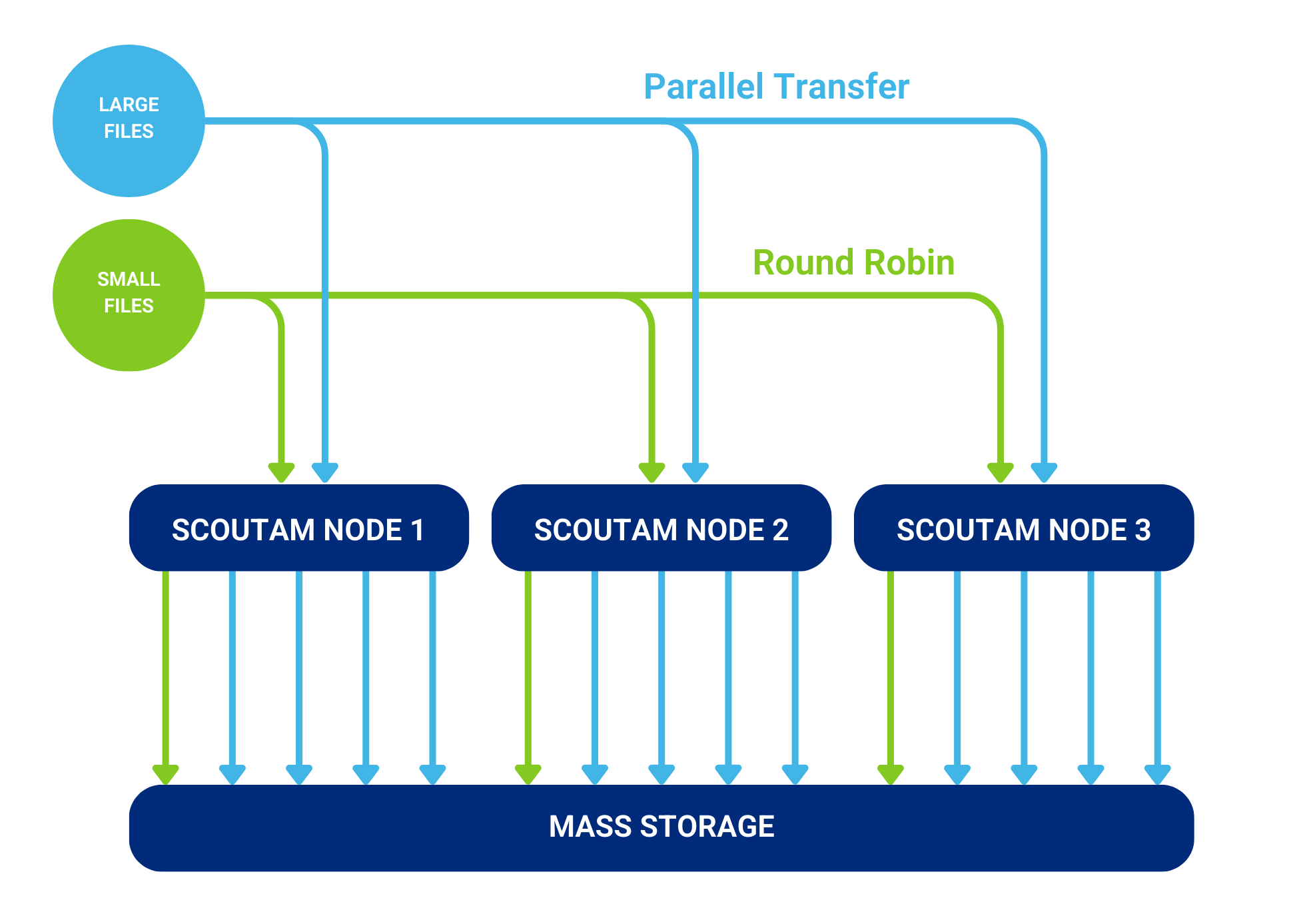
Parallel Transfer
ScoutAM can read and write data to mass storage devices and services through multiple data channels on each node in the cluster simultaneously. Large files or objects may be segmented and written in parallel across a configurable number of data channels or across a range of data channels. Many smaller files or objects may be allocated among channels using a round-robin algorithm.
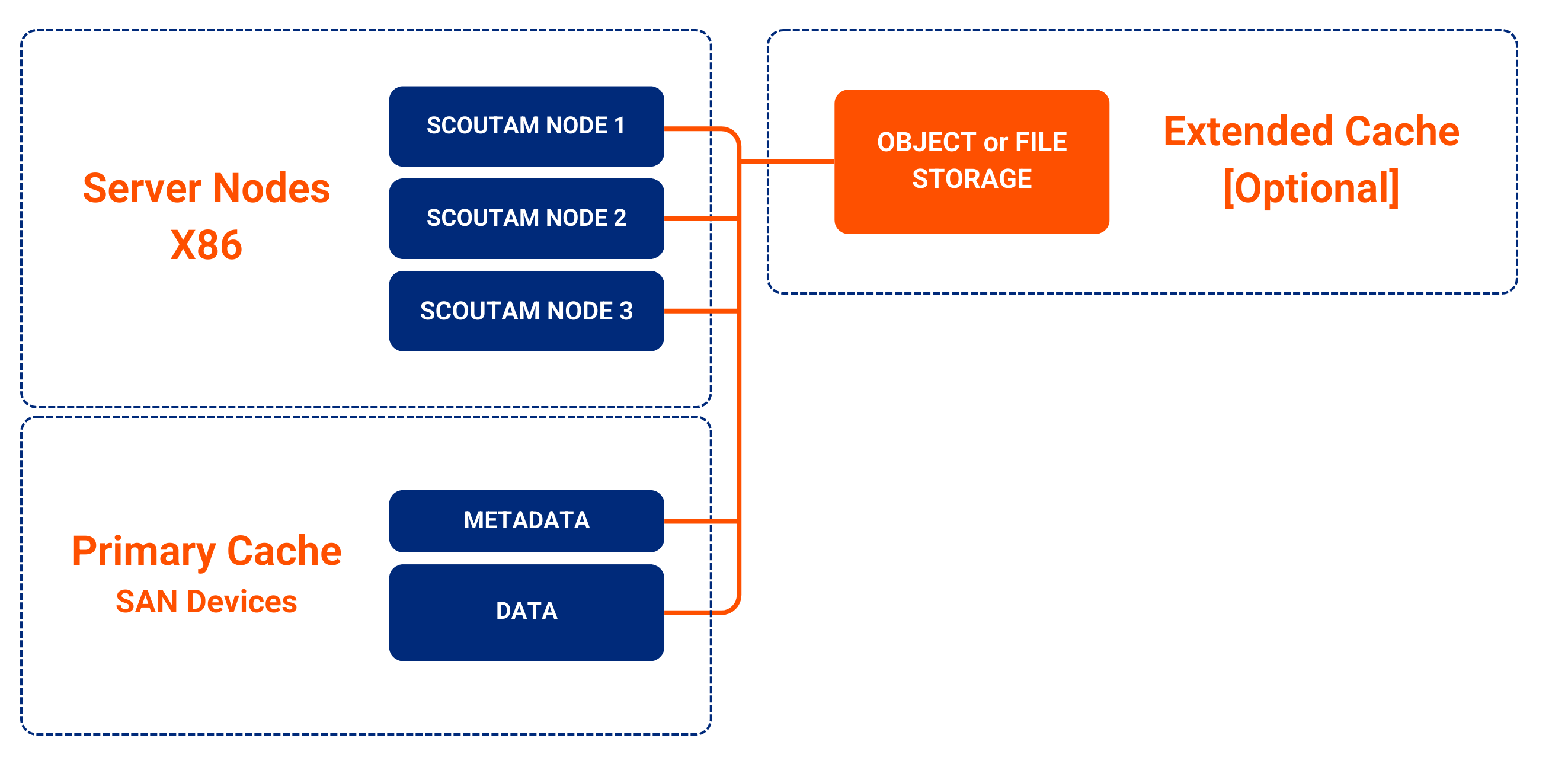
Extended Cache
ScoutAM supports the optional ability to increase cache capacity by adding low-cost S3 object storage devices to augment the capacity of the primary cache. The space available on the extended cache will be fully utilized, and the least used data will be automatically evicted as newer data arrives. Pairing extended cache storage with an all-flash primary cache enables an optimal mix of performance and capacity.
ScoutAM benefits from the rich legacy of VSM and the products that came before it – namely SAM-QFS. Although the code and architecture are new, many years of experience have informed the design and engineering choices behind the ScoutAM platform.
Our vision is for ScoutAM to be not only the most capable mass storage platform in the world, but also the easiest to use.
Rise to the challenge
Connect with Versity today to find out how we can tailor a solution to keep your organization’s data safe and accessible as you advance your mission.