How ScoutFS works
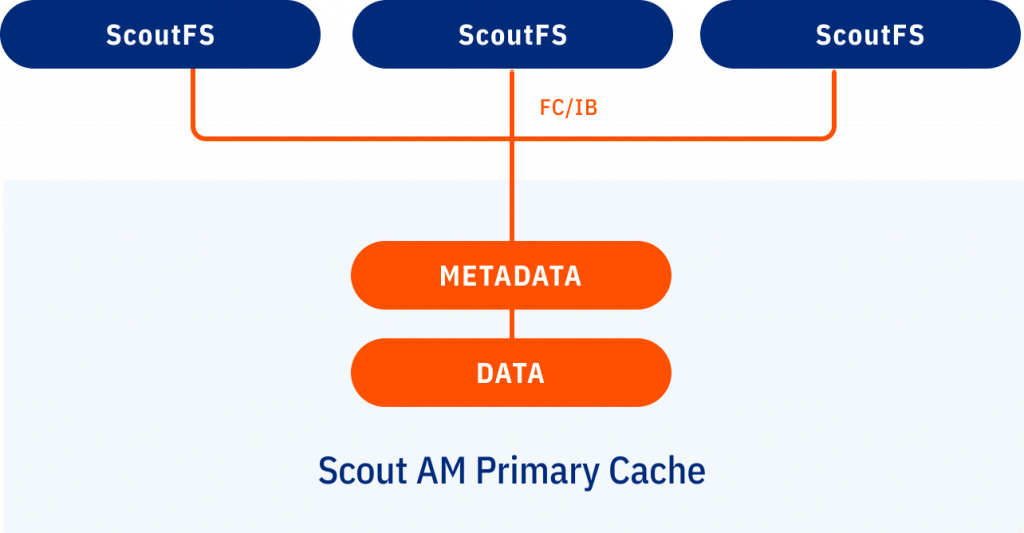
ScoutFS supports mass storage and archiving applications by managing hundreds of billions of metadata records. There is no central metadata controller in a ScoutFS cluster, nor any single point of failure. Metadata is processed on all nodes or a subset of nodes in a ScoutAM cluster.